|
Advisors : Shizhe Chen <shizhe.chen@inria.fr>, Cordelia Schmid <cordelia.schmid@inria.fr> Location : Willow Group, Inria Paris 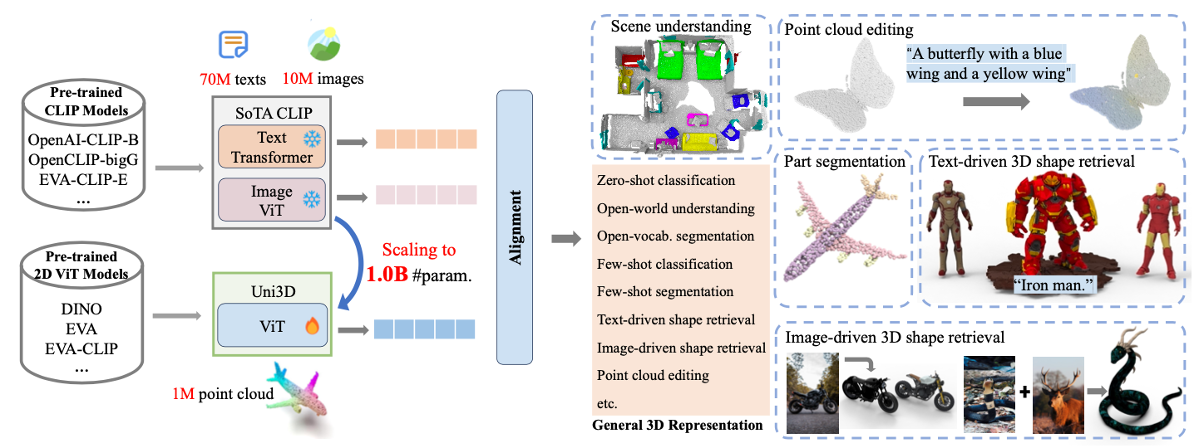
3D understanding [1] has received growing research attention due to the rapid development of 3D sensors and the increasing demand in real world applications such as virtual reality, 3D animations and robotics. Inspired by the success of pre-training 2D vision-and-language models (VLMs) [2], recent work has been exploring the use of 2D VLMs as a bridge to connect 3D and text for 3D understanding [3,4] and generation [5]. These approaches are, however, computationally expensive as they require processing of multi-view images aligned with the 3D data. Therefore, directly pre-training 3D models with cross-modal distillation has emerged [6,7]. To further advance 3D pre-training for various 3D understanding and generation applications, this project aims at pre-training a unified 3D vision and language model based on diffusion techniques [10,11,12]. Description
Requirements We are looking for strongly motivated candidates with an interest in machine learning, computer vision and natural language processing. The project requires a strong background in applied mathematics and excellent programming skills (mostly in Python). If we find a mutual match the project can lead to a PhD in the Willow group.
References
[1] Guo Y, Wang H, Hu Q, et al. Deep learning for 3D point clouds: A survey. IEEE T-PAMI 2020. [2] Gan Z, Li L, Li C, et al. Vision-language pre-training: Basics, recent advances, and future trends. Foundations and Trends in Computer Graphics and Vision, 2022. [3] Jatavallabhula K M, Kuwajerwala A, Gu Q, et al. Conceptfusion: Open-set multimodal 3D mapping. RSS, 2023. [4] Hong Y, Zhen H, Chen P, et al. 3D-LLM: Injecting the 3D world into large language models. arXiv preprint arXiv:2307.12981, 2023. [5] Nichol A, Jun H, Dhariwal P, et al. Point-e: A system for generating 3D point clouds from complex prompts. arXiv preprint arXiv:2212.08751, 2022. [6] Liu M, Shi R, Kuang K, et al. OpenShape: Scaling Up 3D Shape Representation Towards Open-World Understanding. NeurIPS 2023. [7] Zhou J, Wang J, Ma B, et al. Uni3D: Exploring Unified 3D Representation at Scale. arXiv preprint arXiv:2310.06773, 2023. [8] Deitke M, Schwenk D, Salvador J, et al. Objaverse: A universe of annotated 3D objects, CVPR 2023. [9] Deitke M, Liu R, Wallingford M, et al. Objaverse-xl: A universe of 10m+ 3D objects. arXiv preprint arXiv:2307.05663, 2023. [10] Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models. NeurIPS 2020. [11] Wei C, Mangalam K, Huang P Y, et al. Diffusion Models as Masked Autoencoders. ICCV 2023. [12] Rombach R, Blattmann A, Lorenz D, et al. High-resolution image synthesis with latent diffusion models. CVPR 2022. [13] Luo S, Hu W. Diffusion probabilistic models for 3d point cloud generation. CVPR 2021. |
|
Advisors : Shizhe Chen <shizhe.chen@inria.fr>, Stéphane Caron <stephane.caron@inria.fr>, Cordelia Schmid <cordelia.schmid@inria.fr> Location : Willow Group, Inria Paris 
Training high-capacity models on large-scale datasets has led to great success in many fields such as natural language understanding and computer vision. However, such a technique is hard to apply in robotics due to limited data. Recently, an ensembled robotic dataset [1] has been released containing 1M episodes of 527 skills (160266 tasks) from 22 different robots, and has shown to be beneficial to improve performance and develop emergent skills across robots. However, it is still challenging to unify different robot sensors and action spaces and to generalize to new scenarios with new camera configurations and embodiments. This project aims at exploring representations [2,3], action policies [4] and learning algorithms [5,6] that can transfer from the large-scale real robot data to different robots such as the UR5 robot arm in our team at Inria. Description
Requirements We are looking for strongly motivated candidates with an interest in machine learning, computer vision and natural language processing. The project requires a strong background in applied mathematics and excellent programming skills (mostly in Python). If we find a mutual match the project can lead to a PhD in the Willow group.
References
[1] Padalkar A, Pooley A, Jain A, et al. Open X-embodiment: Robotic learning datasets and RT-X models. arXiv preprint arXiv:2310.08864, 2023. [2] Radosavovic I, Xiao T, James S, et al. Real-world robot learning with masked visual pre-training. CoRL 2022. [3] Radosavovic I, Shi B, Fu L, et al. Robot Learning with Sensorimotor Pre-training. CoRL 2023. [4] Shi L X, Sharma A, Zhao T Z, et al. Waypoint-based imitation learning for robotic manipulation. CoRL 2023. [5] Chebotar Y, Vuong Q, Irpan A, et al. Q-transformer: Scalable offline reinforcement learning via autoregressive q-functions. CoRL 2023. [6] Alakuijala M, Dulac-Arnold G, Mairal J, et al. Learning reward functions for robotic manipulation by observing humans. ICRA 2023. |
|
Advisors : Shizhe Chen <shizhe.chen@inria.fr>, Cordelia Schmid <cordelia.schmid@inria.fr> Location : Willow Group, Inria Paris 

The increasing volume of videos online underscores the need for automatic techniques to index and search video contents. While searching for short video clips has received considerable attention, long-term video indexing and searching remain challenging and have been less explored. A compelling solution to facilitate long-term video indexing and searching is to segment long-term videos into chapters as depicted in Figure 1. These chapters are structured and labeled with a short, concise description, enabling users to quickly navigate to areas of interest. A recent work [1] has introduced the VidChapter-7M benchmark dataset for the problem, containing 817K videos with speech transcripts and user-annotated chapters. This project aims to tackle the three tasks defined for VidChapters-7M (see Figure 2), including video chapter generation that requires automatic video segmentation and captioning, video chapter generation with ground-truth boundaries, and video chapter grounding that needs to localize the desired video segment given the chapter title. Description
Requirements We are looking for strongly motivated candidates with an interest in machine learning and computer vision. The project requires a strong background in applied mathematics and excellent programming skills (mostly in Python). If we find a mutual match, the project can lead to a joint PhD in video understanding at Ecole Polytechnique and in the Willow Group of Inria Paris.
References
[1] Yang A, Nagrani A, Laptev I, et al. VidChapters-7M: Video Chapters at Scale. NeurIPS, 2023. [Project page] [2] Yang A, Nagrani A, Seo P H, et al. Vid2seq: Large-scale pretraining of a visual language model for dense video captioning. CVPR 2023. [3] Lei J, Berg T L, Bansal M. Detecting moments and highlights in videos via natural language queries. NeurIPS 2021. [4] Zhou L, Xu C, Corso J. Towards automatic learning of procedures from web instructional videos. AAAI 2018. [5] Huang G, Pang B, Zhu Z, et al. Multimodal pretraining for dense video captioning. AACL-IJCNLP 2020. [6] Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models. NeurIPS 2020. [7] Chen S, Sun P, Song Y, et al. Diffusiondet: Diffusion model for object detection. CVPR 2023. |